Textanalysen
Basis von Textanalysen sind Tausende von Texten, die von Psychologen bestimmten Ausprägungen zuordnet wurden. Mit Hilfe der „Künstlichen Intelligenz“ werden neue Texte mit diesem möglichst großen Schatz an zugeordneten Informationen verglichen. Daraus lassen sich Zuordnungen mit bestimmten Wahrscheinlichkeiten ableiten. Zum Beispiel weist eine Formulierung wie „ich möchte die Dinge unter Kontrolle haben“ auf die Ausprägung „Machtmotiv“ hin. Es ist logisch, dass eine Maschine solche Berechnungen schneller und im Ergebnis zutreffender machen kann, als ein Mensch es zu tun vermag.
Eine weitere Möglichkeit ist es, die „Maschine“ mit jeweils zwei Informationspaketen zu jedem Probanden zu füttern. Das sind zum einen Texte, die jemand zu bestimmten Fragen oder Aufgaben geschrieben hat – und zum anderen sind es die Daten seiner Ausprägungen, die mit einer validen Persönlichkeitsanalytik (möglichst aus verschiedenen Tests) errechnet wurden. In beiden Systemen bestimmt die Menge der Texte die Qualität der Textanalyse.
Für die Entwicklung des ECL (extended computer learning) nutzen die IPM Autoren diese Ausgangslage für eine weitere Betrachtungsebene. Wenn aufgrund der Ergebnisse aus dem M.L. und den Textauswertungen im Vergleich zu den Ausprägungen der Probanden klar ist, wer bevorzugt welche Worte nutzt, ist für jedes Wort eine Prognose möglich sein, die sagt, mit welcher Wahrscheinlichkeit es für eine Reihe definierter Ausprägungen spricht. Das Wort „wir“ findet sich zum Beispiel häufiger bei Kontakt- oder Integrationstypen – die Worte „ich“ oder „man“ finden sich dagegen häufiger in den Texten von Individualisten oder rationalen Typen.
Jetzt und in den kommenden Jahren werden sich im System OPEN IPM unterschiedliche Maschinen-Lernsysteme und Algorithmen, wie das ECL gegenseitig unterstützen – also voneinander lernen. Doch schon heute werden beachtlich detaillierte Ergebnisse erreicht.
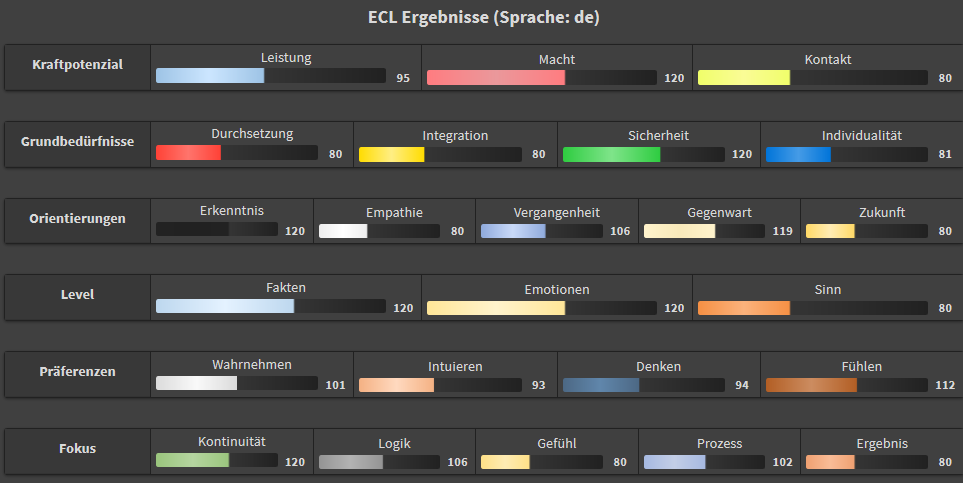
Beim oben genannten Beispiel „ich möchte die Dinge unter Kontrolle haben“
zeigen sich diese Detail-Ergebnisse:
Hier wird die IPM Skala 0..200 mit dem Mittelwert 100 über alle Texte einer
bestimmten Kategorie genutzt. Ein Transfer in andere Skalen ist möglich und
auch für das API vorgesehen.
Normwerte
Als normierten Input verwendet ECL die zusammenfassende Auswertung aller vorliegenden Texte verschiedener Quellen, wie Bildbeschreibungen, textliche Antworten zu verschiedenen Fragen und eine umfangreiche Prosasammlung moderner Autoren, inklusiv Presse und Werbetexte. Die Ergebnisse zu einem neu gegebenen Text sagen damit, inwieweit die genutzten Worte von diesen Durchschnittswerten abweichen.
Im obigen Beispiel, untere Zeile werden vergleichsweise viele Worte genutzt, die typisch sind für Menschen mit einem größeren Fokus auf „Kontinuität“ und sehr wenige, die typisch sind für eine Ergebnis-Fokussierung.
Situationsbezogene Ergebnisse
Während der Entwicklung wurde die Frage untersucht, inwieweit die Emotionalität der Sprache und damit die abzuleitenden Ausprägungen kontextspezifisch variieren. Hierzu wurden in einem Test unterschiedliche Szenarien abgefragt, zum Beispiel „Was möchten Sie beruflich erreichen?“ versus „Woran erinnern Sie sich gerne, wenn Sie an einen schönen Urlaub denken?“ Erwartungsgemäß prägte bei fast allen Probanden der so gegebene Kontext die Wahl der Worte sehr deutlich.
Es wurden weitere Szenarien untersucht. In einer Testumgebung wurden Beratungsgespräche zu technischen Fragen aufgezeichnet. In anderen Projekten wurden typische Stellenbeschreibungen sowie ein Katalog von Berufsbildern analysiert. In jedem Fall zeigten sich mehr oder weniger starke Abweichungen von den Normwerten. Eine Aussage wie „Ich möchte die Dinge unter Kontrolle haben“ wird mit hoher Wahrscheinlichkeit eher für eine berufliche Situation als für einen genussreichen Urlaub gelten.
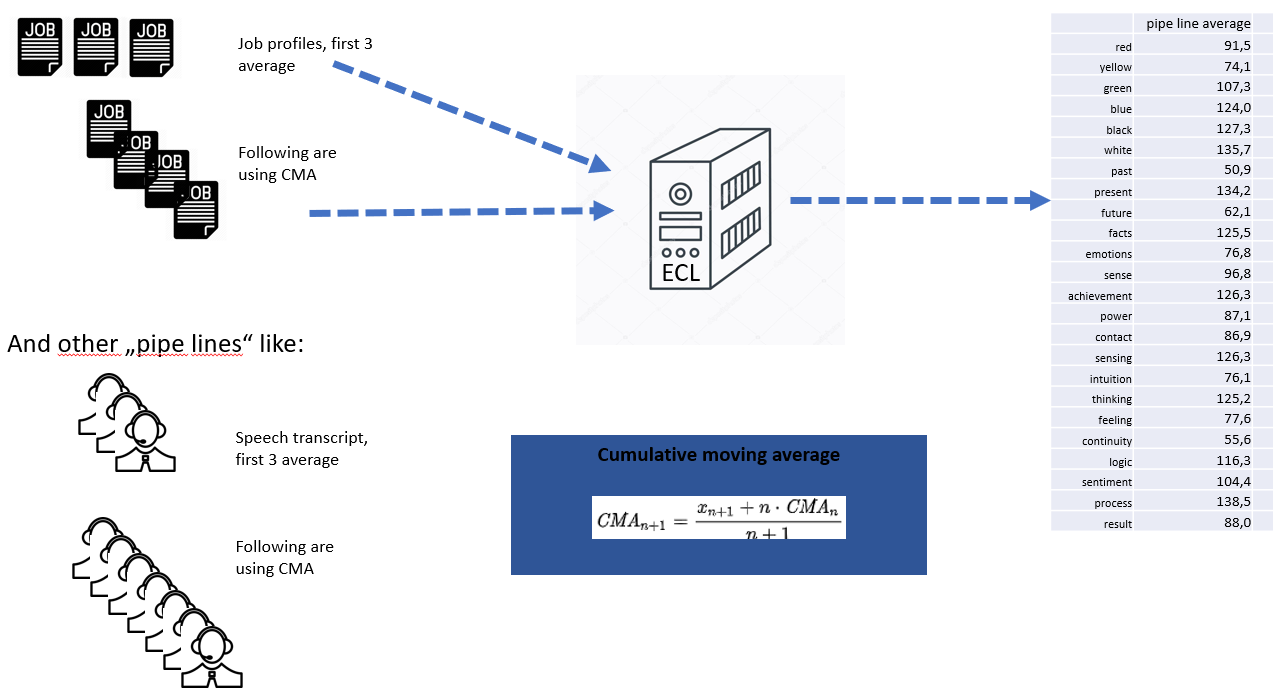
Pipelining
Diese Erfahrungen führten zu einer kontextspezifischen Auswertung. Dabei werden die sich aus einer Reihe von Tests zu einem gegebenen Kontext ermittelten „Durchschnittswerte“ auf ihre durchschnittliche Abweichung von den „Normwerten“ überprüft. Für jede Ausprägung innerhalb einer Pipeline werden kumulierte Durchschnittswerte (CMA) gebildet, die dann zu einer statistischen Korrektur genutzt werden.
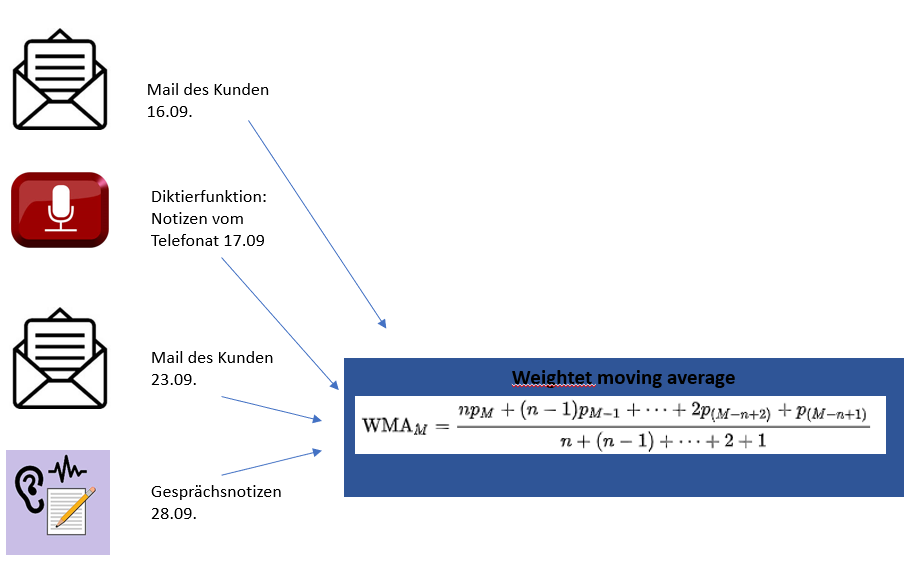
Projektspezifisch lässt sich das um die Weightet moving average Methode ergänzen. Dabei wird der Umfang der Informationen (Anzahl der Zeichen) als Gewichtungsfaktor genutzt. Hier am Beispiel die Auswertung der Kommunikation mit einem Kunden:
Integration in bestehende Software-Lösungen
Die Textanalytik kann als Webservice genutzt werden. Ein Request wird mit einem Text geschickt. Dabei wird entweder eine Ermittlung der Normwerte beauftragt oder zu einer vorher vereinbarten Pipeline eine statistische Anpassung angefordert. Der Response besteht, soweit nichts anderes vereinbart wurde, aus den 24 Ausprägungswerten. Diese werden entweder von der vorhandenen Software-Lösung weiterverarbeitet oder dienen als Parameter für den Abruf weiterer Auswertungen oder Ergebnisdarstellungen.