Text Analyses
Text analyses are based on thousands of texts that psychologists have assigned to certain forms. With the help of "artificial intelligence", new texts are compared with this treasure trove of assigned information. From this, classifications with certain probabilities can be derived. For example, a phrase like "I want to have things under control" refers to the expression "power motive". It is logical that a machine can make such calculations faster and more accurate than a human can do.
Another possibility is to feed the "machine" with two information packets to each test person. These are, on the one hand, texts that someone has written about certain questions or tasks - and, on the other hand, the data of his characteristics that were calculated with a valid personality analysis (if possible from different tests). In both systems, the quantity of texts determines the quality of the text analysis.
For the development of ECL (extended computer learning), the IPM authors use this starting point for a further level of consideration. If it is clear from the results from the M.L. and the text evaluations in comparison to the values of the test persons who prefers which words, a prognosis is possible for each word, which says with which probability it speaks for a series of defined values. For example, the word "we" is found more frequently in contact or integration types - the words "I" or "man", on the other hand, are found more frequently in the texts of individualists or rational types.
Now and in the coming years, different machine learning systems and algorithms, such as ECL, will support each other in the OPEN IPM system. But even today, remarkably detailed results are being achieved.
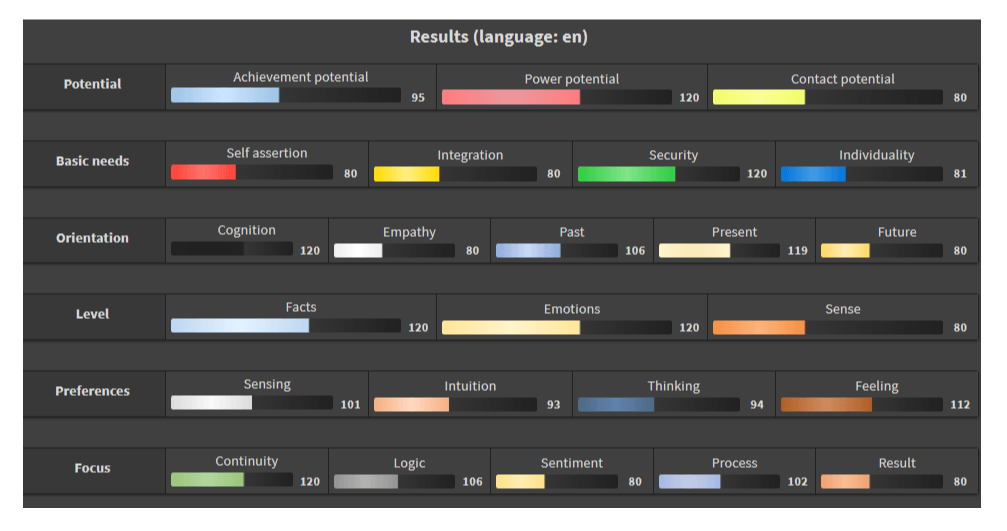
The above example "I want to have things under control" shows these detailed
results:
Here the IPM scale 0..200 with the mean value 100 over all texts of a certain
category is used. A transfer into other scales is possible and also intended
for the API.
Normal values
As standardized input, ECL uses the summarizing evaluation of all available texts from different sources, such as image descriptions, textual answers to various questions and an extensive prose collection of modern authors, including press and advertising texts. The results for a newly given text thus indicate the extent to which the words used deviate from these average values.
In the example above, bottom line, comparatively many words are used that are typical for people with a greater focus on "continuity" and very few that are typical for a result focus.
Situational results
During the development, the question was examined to what extent the emotionality of the language and thus the characteristics to be derived vary from context to context. In a test, different scenarios were asked, for example "What do you want to achieve professionally?" versus "What do you like to remember when you think of a nice holiday? As expected, the choice of words was clearly influenced by the context of almost all test persons.
Further scenarios were examined. Consultations on technical issues were recorded in a test environment. In other projects, typical job descriptions and a catalogue of job descriptions were analysed. In each case, deviations from the standard values were more or less pronounced. A statement like "I want to have things under control" is more likely to apply to a professional situation than to an enjoyable holiday.
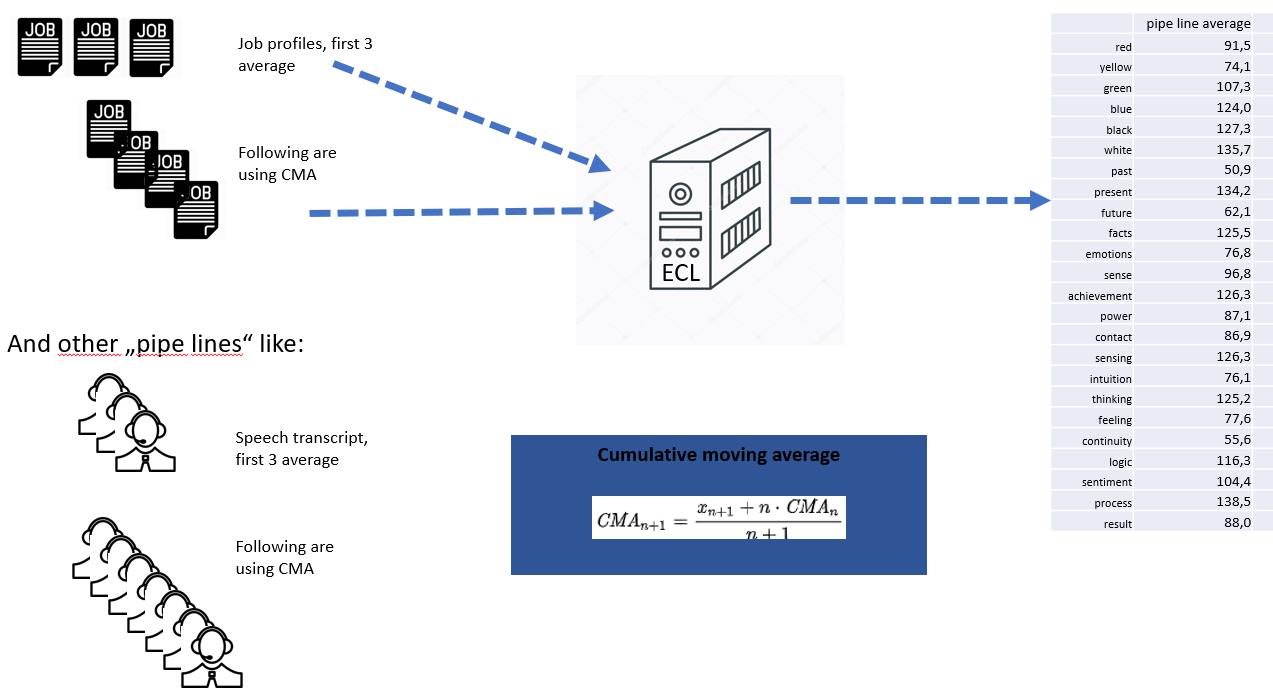
Pipelining
These experiences led to a context-specific evaluation. The "average values" determined from a series of tests for a given context are checked for their average deviation from the "standard values". Cumulated average values (CMA) are formed for each characteristic within a pipeline, which are then used for a statistical correction.
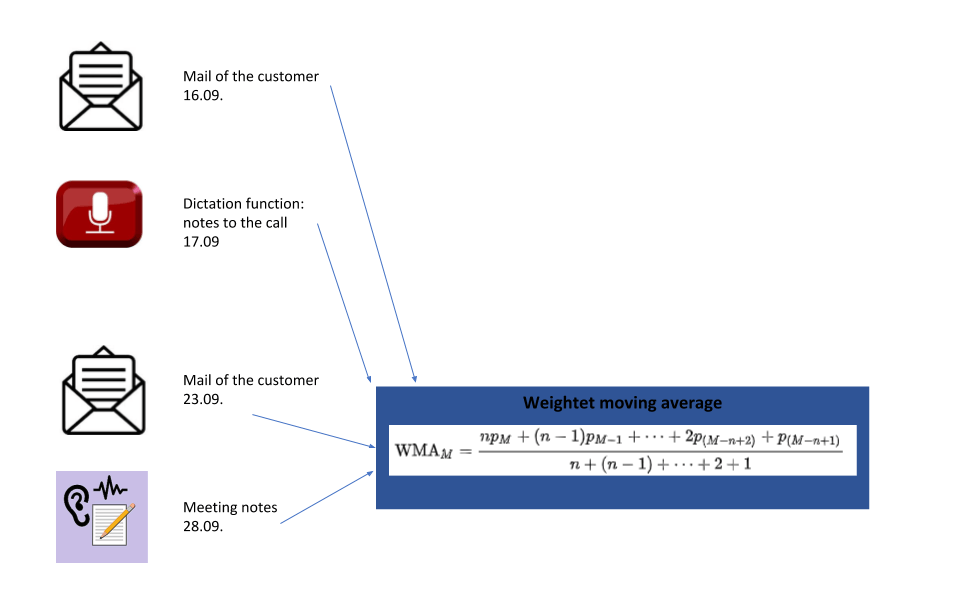
The Weightet moving average method can be added to this for specific projects. The amount of information (number of characters) is used as the weighting factor. This example shows the evaluation of the communication with a customer:
Integration into existing software solutions
Text analytics can be used as a web service. A request is sent with a text. Either a determination of the standard values is commissioned or a statistical adjustment to a previously agreed pipeline is requested. Unless otherwise agreed, the response consists of the 24 values. These are either processed further by the existing software solution or serve as parameters for retrieving further evaluations or result presentations.